Motion retargeting aims at transferring a given motion from a source character to a target one. The task becomes increasingly challenging as the differences between the body shape and skeletal structure of input and target characters increase.
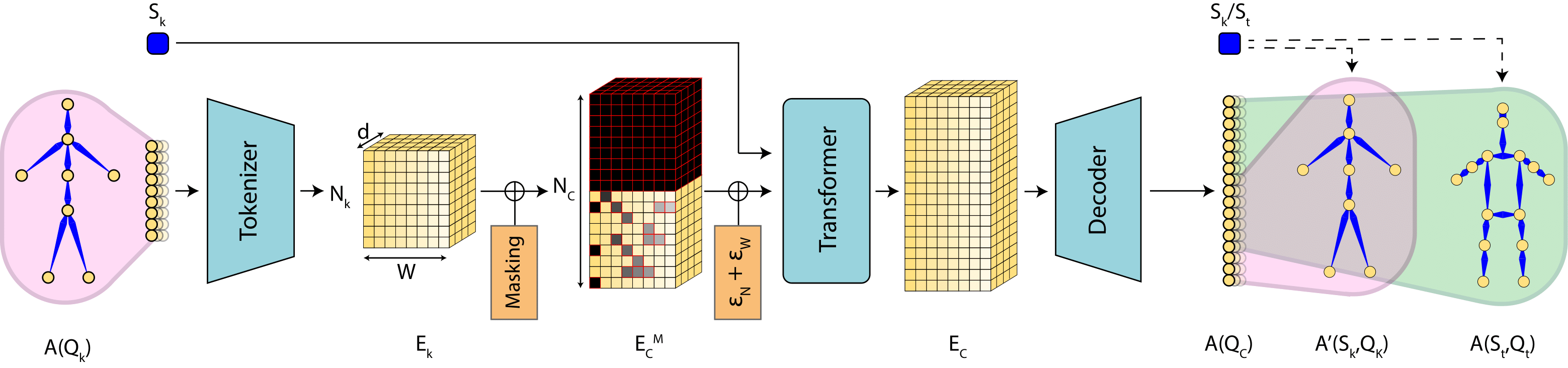
We present a novel approach for motion retargeting between skeletons whose goal is to transfer the motion from a source skeleton to a target one in a different format. Our approach works when the two skeletons differ in scale, bone length, and number of joints. Surpassing previous approaches, our method can also retarget between skeletons that differ in hierarchy and topology, such as retargeting between animals and humans. We train our method as a transformer using a random masking strategy both in time and space, aiming at reconstructing the joints of the masked input skeleton to obtain a deep representation of the motion. At testing time, our proposal can retarget the input motion to different skeletons, reconstructing the disparities between the source and the target.
Our method outperforms state-of-the-art results on the Mixamo dataset, which features a high variance between skeleton formats. Moreover, we show how our approach can effectively generalize to different domains by transferring between human motion and quadrupeds, and vice-versa.
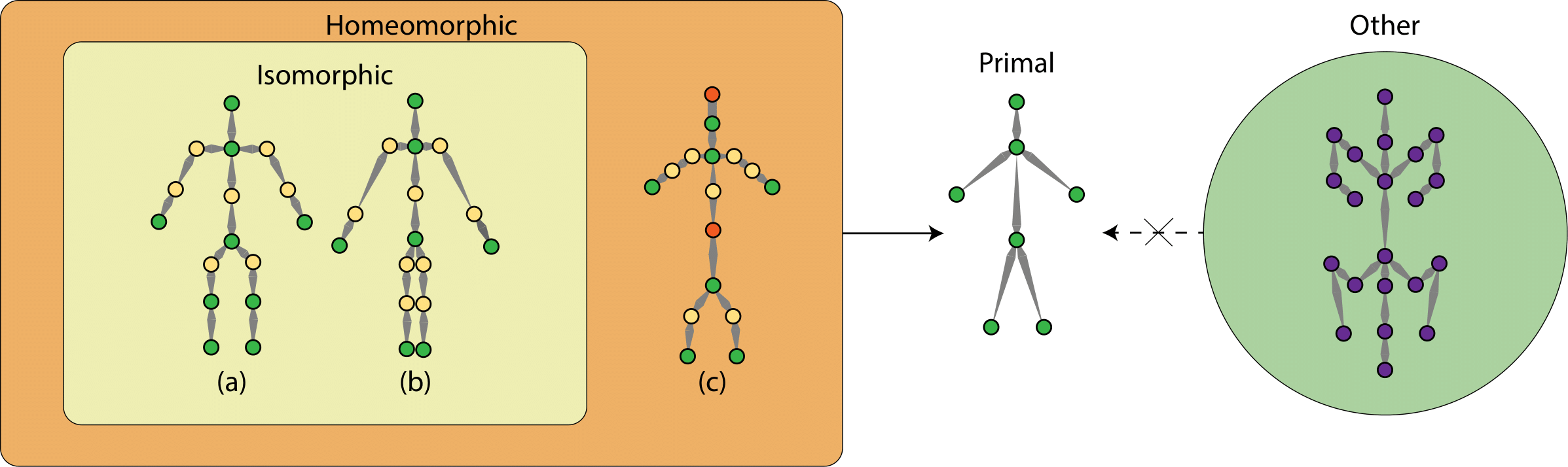 Examples of isomorphic skeletons are (a) and (b), which have the same joints but varying bone lengths. Both (a) and (b) are homeomorphic to the skeleton (c), which has a different number of joints. They are defined as homeomorphic because they can all be reduced to a common primal skeleton (d). The skeleton of a quadruped (e) is neither homeomorphic nor isomorphic to the others because the topology is changed and thus (e) cannot be reduced to the common primal skeleton.
Examples of isomorphic skeletons are (a) and (b), which have the same joints but varying bone lengths. Both (a) and (b) are homeomorphic to the skeleton (c), which has a different number of joints. They are defined as homeomorphic because they can all be reduced to a common primal skeleton (d). The skeleton of a quadruped (e) is neither homeomorphic nor isomorphic to the others because the topology is changed and thus (e) cannot be reduced to the common primal skeleton.
 Qualitative results for the retargeting between isomorphic skeletons. The outputs are overlaid with the ground truth, represented by the green skeleton. Our results demonstrate greater stability and alignment with the ground truth. In the second row, we present the mesh visualization. Notably, our method achieves superior qualitative results even without employing any mesh collision penalizer.
Qualitative results for the retargeting between isomorphic skeletons. The outputs are overlaid with the ground truth, represented by the green skeleton. Our results demonstrate greater stability and alignment with the ground truth. In the second row, we present the mesh visualization. Notably, our method achieves superior qualitative results even without employing any mesh collision penalizer.
 Our approach can retarget from real-world characters, whose motion can be modeled by a common SMPL mesh, even with challenging and unseen motion such as backflip.
Our approach can retarget from real-world characters, whose motion can be modeled by a common SMPL mesh, even with challenging and unseen motion such as backflip.